|
I am currently working as a Student Researcher at WangLab affiliated with Vector Institute and University Health Network, proudly advised by Prof. Bo Wang. I completed my Master's degree in ECE, specialized in Machine Learning at the University of Toronto advised by Prof. Deepa Kundur and by Prof. Yuri Lawryshyn. My research focuses on Machine Learning, Computational Biology, Computer Vision and Natural Language Processing. Apart from my research, I am also interested in Deep Learning and Deep Reinforcement Learning with the focus of transfer learning, imitation learning, model-based RL. My ultimate goal is to build robust, privacy-preserved, and interpretable algorithms with human like ability to generalize in real-world environments by using data as its own supervision.
Throughout my life, I have approached every challenge with enthusiasm, creativity, and a ceaseless desire to achieve success. This passion and drive have paved the way to countless opportunities, unique experiences, and excellent relationships, both personally and professionally. I enjoy working with people and discussing ideas, so please do not hesitate to contact me. Outside of academics, I enjoy basketball, hiking, biking, running ( pretty much every sport ! ). If you would like to chat, feel free to send me an email. |

|




|
 M.A.Sc in Electrical and Computer Engineering @
M.A.Sc in Electrical and Computer Engineering @
 B.Eng in Electronics and Communication Engineering @
B.Eng in Electronics and Communication Engineering @
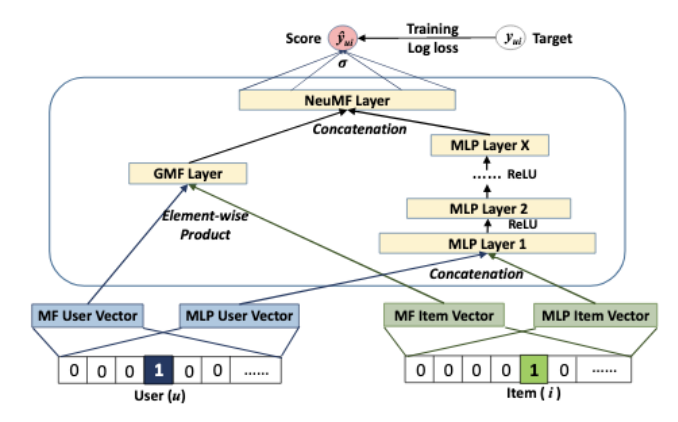
|
|
|
|


|
|

|
|

|
|

|
|

|
|

|
|

|
|

|
|
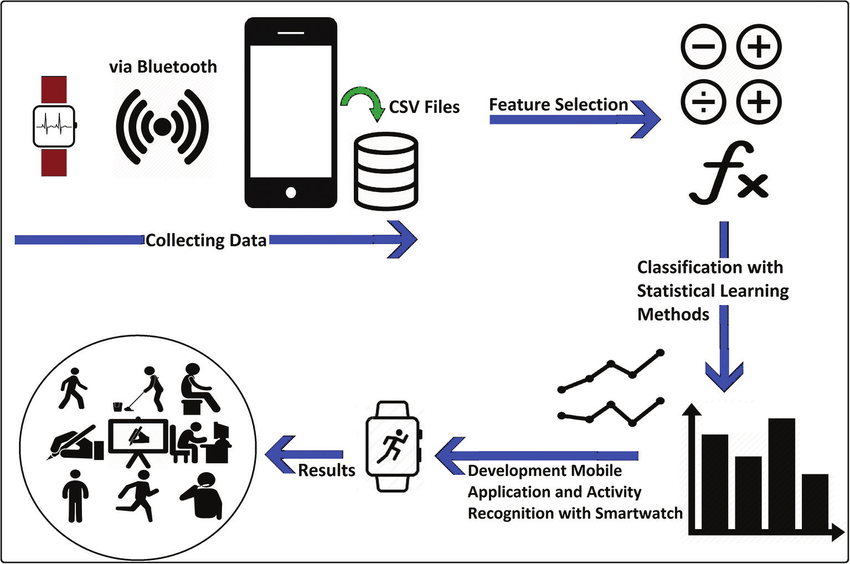
|
|

| |
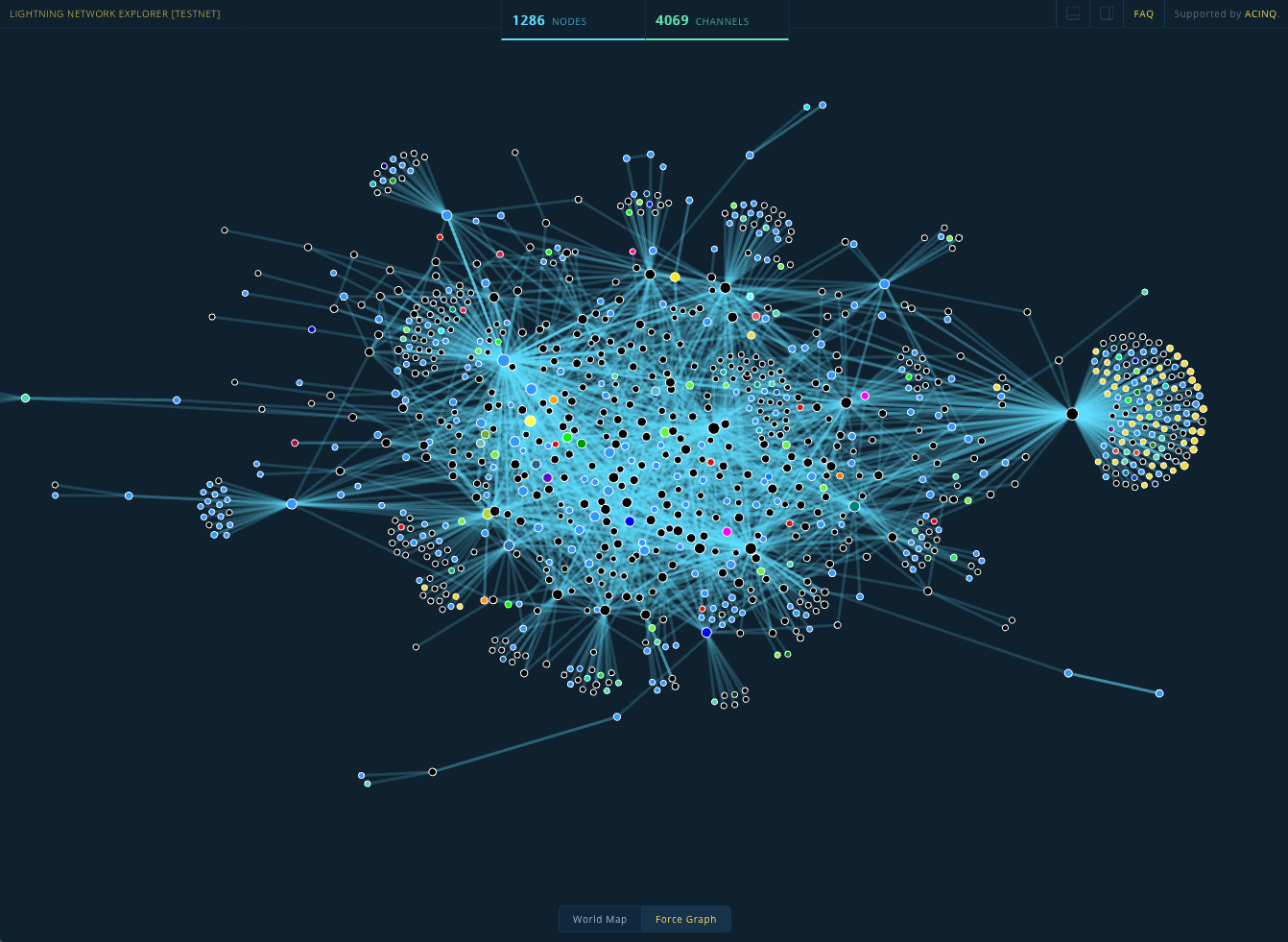
| |

|
|

|
|

|
|

| |

|
|

|
|
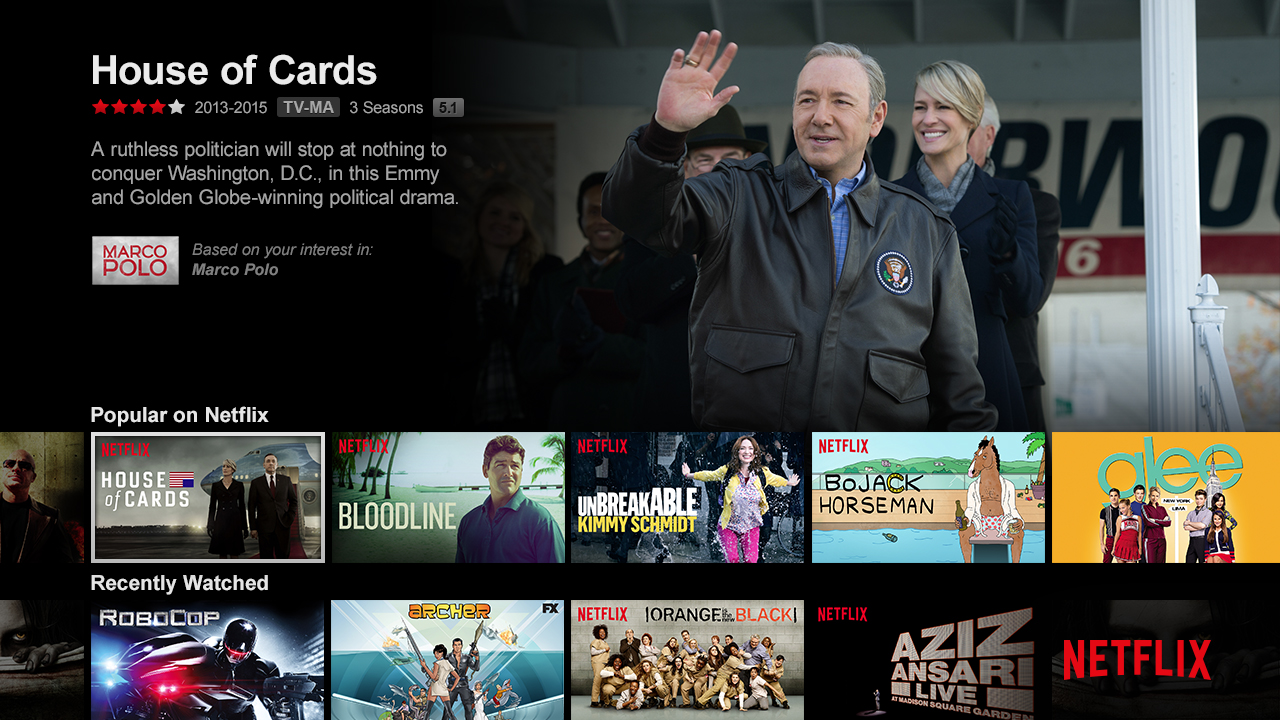
|
|

|
|
|
|
Template: this/that, ce/cette, das/der, kono/sono and zhege/nage. |